LooPIN - 主网更新报告

LooPIN 的测试网于 2023 年 4 月 9 日启动,至今已经过去了 190 多天。在此期间,该协议经历了广泛的测试。虽然其稳定性和可靠性已得到确认,但我们也发现了几个潜在的改进点。这篇博客总结了我们的测试网报告,并重点介绍了为主要测试阶段实施的变更。
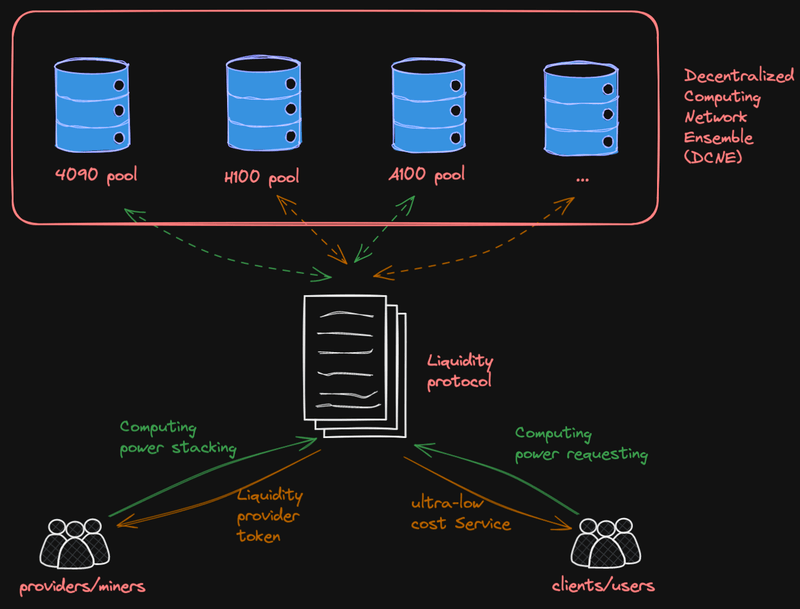
流动性提供者和计算力质押证明 (Proof-of-Computing-Power-Staking, PoCPS)
在 LooPIN,我们的目标是提供一个可靠的协议,为用户提供稳定的计算资源,同时确保用户和流动性提供者(即提供计算资源的参与者)的长期参与。流动性提供者提供的计算资源的稳定性对于提高协议的实用性至关重要。我们的目标是创建一个系统,用户可以持续依赖 LooPIN,而流动性提供者则有动力提供稳定的计算力。然而,在我们的测试网阶段出现了几个问题:
- 计算资源的稳定性:我们最初提出的计算力稳定性证明 (PoCPS) 已被证明不足以实现企业级稳定性。一些流动性提供者的 GPU 通过了 PoCPS 验证,但当用户购买 GPU 时间时,这些机器未能满足其性能要求。新节点在测试网阶段缺乏适当的测试期,导致资源可用性不稳定。
- 流动性代币波动性:虽然这个问题在测试网阶段没有出现,但我们预计在主网中,流动性提供者可能会大量出售 LooPIN 代币,促使其他人也这样做。这可能导致代币价格不稳定并阻碍协议的可扩展性。
- 数据隐私担忧:AI 研究人员,我们的一个关键用户群体,对数据安全表示担忧。原始 PoCPS 算法没有包含保护用户数据隐私的措施。
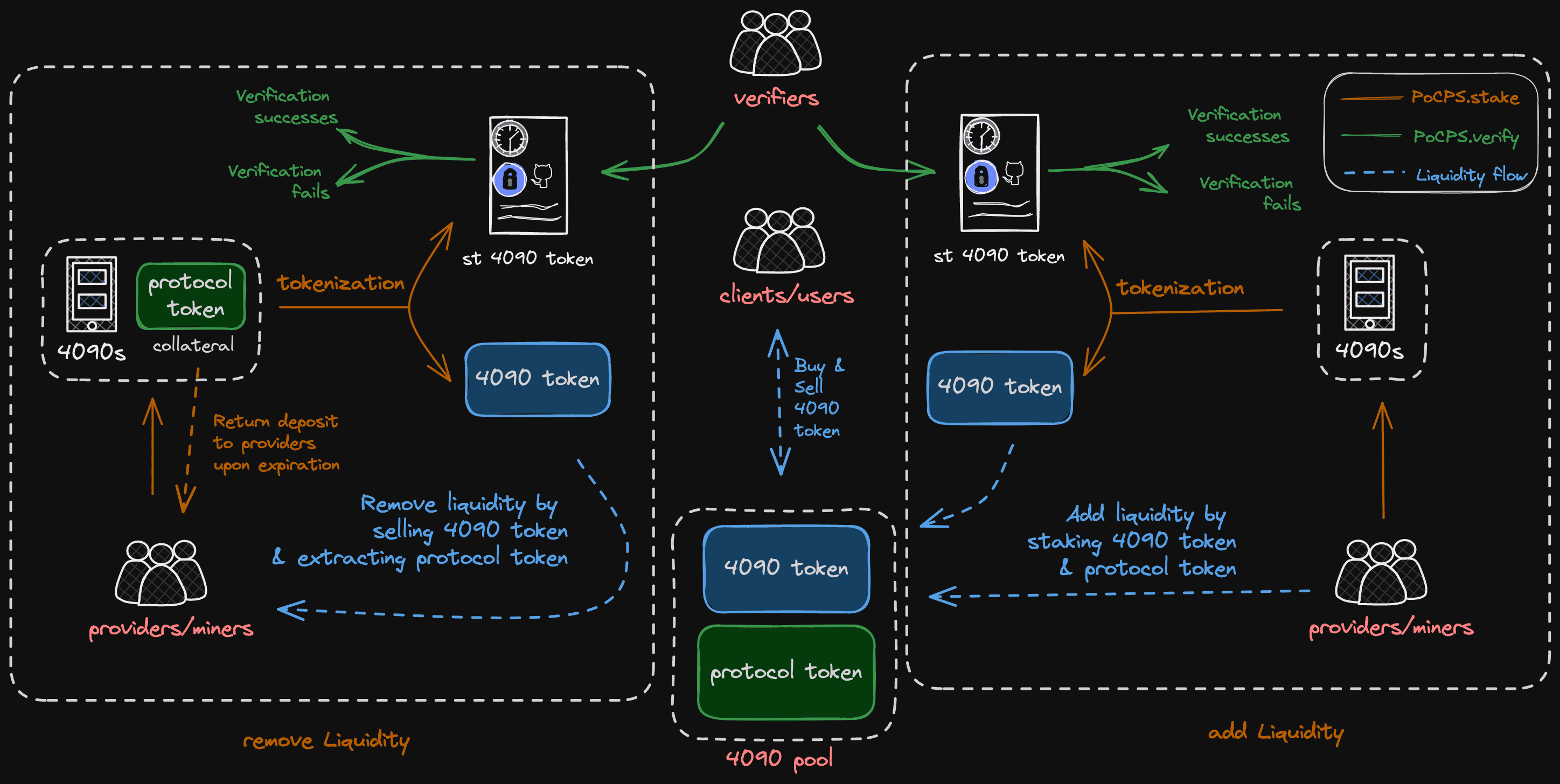
虽然原始 PoCPS 是一个可靠的工作量证明 (Proof of Work, PoW) 算法,旨在防止几个主要的攻击向量,但它没有解决稳定性、可扩展性或隐私的关键需求。为了解决这些挑战,同时保持我们协议的 PoW 基础,我们扩展了原始 PoCPS 框架,包括:
其中:
- PoT (时间证明, Proof-of-Time) 解决基于时间的稳定性测试,
- PoL (忠诚度证明, Proof-of-Loyalty) 专注于流动性管理和控制,
- PoP (隐私证明, Proof-of-Privacy) 增强用户数据的隐私保护,以及
- PoW (工作量证明, Proof-of-Work) 代表我们白皮书中提出的原始 PoCPS。
这个新结构旨在改善稳定性、可扩展性和隐私,同时保留我们协议的核心元素。
PoT、PoL、PoP 和 PoW 可以定义如下:
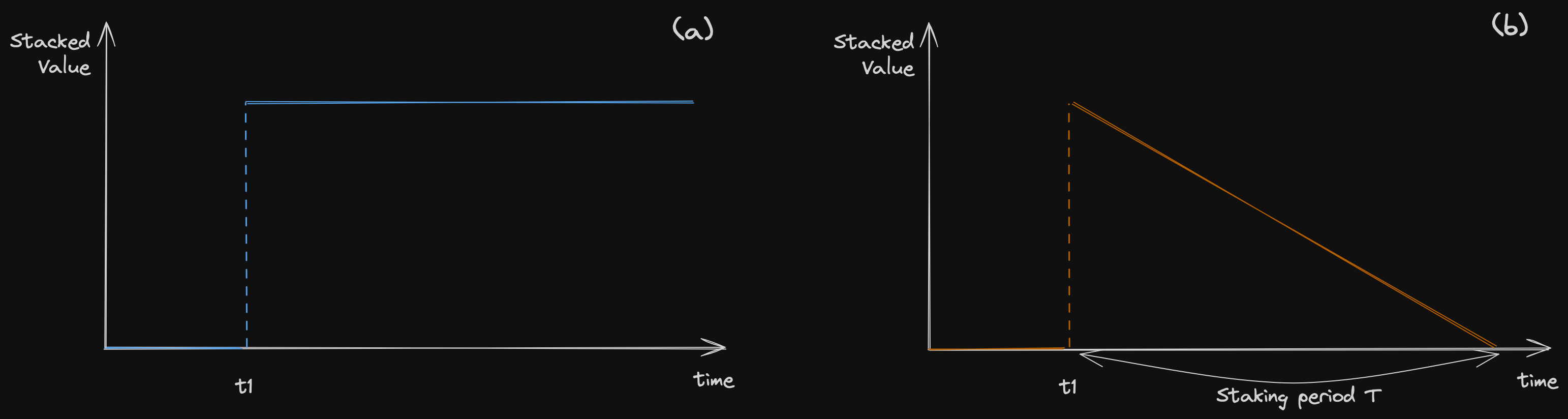
PoT (时间证明): 时间证明奖励基于节点参与协议的时间长短。节点保持活跃的时间越长,它可以获得的奖励就越多,上限由网络中的节点数量决定。PoT 的公式是:
其中
- 是节点在协议中的参与时间,
- 是节点获得全额奖励前的初始期(也称为爬坡期),
- 决定新节点的奖励比例。
目前,
- ,这意味着新添加��的节点在达到 之前可以获得总奖励的 10%,
- 在主网阶段, 设定为 30 天。
忠诚度证明 (Proof-of-Loyalty, PoL): 忠诚度证明与节点出售的 LooPIN 代币数量有关。出售更多代币的节点表现出较低的忠诚度,因此获得较低的奖励。PoL 的计算公式为:
其中:
- 指节点当前持有的 LooPIN 代币数量,
- 指节点在其生命周期内铸造的 LooPIN 代币总量,
- 指控制出售大部分代币的节点的奖励减少程度的参数。
目前 的值为 7.324。
隐私证明 (Proof-of-Privacy, PoP): 隐私证明根据节点保护用户数据的程度来奖励节点。保持更高隐私标准的节点获得更高的奖励。PoP 的计算公式为:
其中:
- 指节点的隐私级别,
- 指基准隐私级别,
- 指决定隐私标准较低的节点奖励减少程度的参数。
目前 。
工作量证明 (Proof-of-Work, PoW): 工作量证明奖励基于节点与网络中类似图形处理器 (GPU) 的性能比较。性能更好的节点获得更高的奖励。PoW 的计算公式为:
其中:
- 指节点的性能水平,
- 指基准性能水平,
- 指决定性能不佳的节点奖励减少程度的参数。
目前 。
计算能力池的流动性
在我们的测试网 (testnet) 阶段,协议要求流动性提供者为他们添加到流动性池(一种用于存储和管理可用计算资源的机制)的每台机器抵押相当于 24 小时计算能力的 LooPIN 代币。最初的理由是 LooPIN 代币数量有限,抵押更大数量会具有挑战性。此外,矿工之间的代币转移不常见,使得数据中心难以参与。随着测试网的进行,一些问题变得明显:
- 由于流动性池深度有限,计算能力价格经历了显著波动。例如,A100 GPU(一种高性能图形处理器)的价格在一天内从 1.3 波动到 0.9,这种情况经常发生。
这种波动性对我们的大学和人工智能 (AI) �研究实验室用户来说尤其成问题,他们敦促我们稳定价格并使协议更加用户友好。为解决这些问题,我们将流动性提供者的抵押要求从 24 小时(1 天)增加到 7 天(1 周)。随着抵押的计算小时数和 LooPIN 代币增加,流动性池的深度将增加,将价格波动性降低到测试网阶段的 14%。我们可以进一步增加抵押要求,但我们将此留给下一阶段。
投机性资源销售
在测试网阶段,协议允许投机卖家以小时为单位提供他们的计算资源,最少 1 小时,最多 24 小时。这种设置的目的是增强流动性,给予卖家尽可能多的灵活性来销售他们的计算能力。然而,测试网揭示了几个问题:
- 对于以 1 小时为单位销售的计算能力,协议难以在时间耗尽前匹配用户,导致未使用时间的比例较高。
- 大多数卖家来自数据中心,他们的销售需求超过了 24 小时的最大限制。
鉴于 LooPIN 旨在成为一个高效的协议,减少未使用时间的比例至关重要。因此,我们在主网 (mainnet) 阶段将销售时间单位调整为 1 天,最短销售期为 1 天,最长为 7 天。这也意味着为从池中提取流动性而销售的计算能力必须保持机器的可用性更长时间。
此外,为了进一步提高我们的交易网络的稳定性,我们正在将卖家需要提供的保证金 (抵押品) 金额从原来的 1 倍提高到 100 倍所售出 GPU 计算时间的价值。这项调整有助于防止一些不怀好意的卖家利用代币价格的波动来进行投机获利,从而损害网络的稳定运行。
买家
在测试网阶段,协议允许买家以小时为单位购买计算资源,最少 1 小时,最多 24 小时。然而,大学和 AI 研究实验室的用户强调能够延长原始购买时间和提前终止实例的重要性。作为回应,我们在主网阶段实施了这些功能,使协议更加易于使用和用户友好。
流动性池
根据初创公司和研究实验室的反馈,我们正在为 AI 训练添加更多企业级 GPU。由于 AI 训练需要额外的随机存取内存 (RAM) 和每秒万亿次浮点运算 (TFlops),我们将在我们的流动性池中包括 H100(SXM 或 PCIe)和 L40(L40s)GPU,并提供抵押奖励。我们还将在不久的将来引入下一代 GPU,如用于 AI 推理任务的 RTX 5090。此外,我们将根据使用情况和租赁历史逐步淘汰较旧或不太受欢迎的 GPU,如 RTX 4080/3080、RTX 4070/3070、Tesla T4 和 V100。